
# MySQL - MVCC
# 一致性非锁定读和锁定读
# 一致性非锁定读
对于 一致性非锁定读 (Consistent Nonlocking Reads) (opens new window) 的实现, 通常做法是加一个 版本号 或者 时间戳 字段, 在更新数据的同时更新版本号或者时间戳. 查询时, 将当前可见的版本号与对应记录的版本号进行对比, 如果记录的版本号小于可见版本号, 则表示该记录可见
在 InnoDB 存储引擎中, 多版本控制 (multi versioning) (opens new window) 就是对非锁定读的实现. 如果读取的行正在执行 DELETE 或 UPDATE 操作, 这时读取操作不会去等待行上锁的释放. 相反的, InnoDB 存储引擎会去读取行的一个快照数据, 对于这种读取历史数据的方式, 称之为 快照读 (snapshot read)
在可重复读 ( Repeatable Read) 和读已提交 (Read Commit) 两个隔离级别下, 如果执行普通的 SELECT 语句 (不包括 select .... lock in share mode, select ... for update) 则会使用 一致性非锁定读 (MVCC). 并且在 可重复读 (Repeatable Read) 下 MVCC 实现了可重复读和防止部分幻读
# 锁定读
如果执行的是下列语句, 就是 锁定读 (Locking Reads) (opens new window)
select ... lock in share modeselect ... for updateinsert,update,delete操作
在锁定读下, 读取的是数据的最新版本, 这种读也被称为 当前读 (current read). 锁定读会对读取到的记录加锁 :
select ... lock in share mode: 对记录加S锁, 其他事务也可以加S锁, 如果加X锁则会被阻塞select ... for update,insert,update,delete: 对记录加X锁, 且其他事务不能加任何锁
在一致性非锁定读下, 即使读取的记录已经被其他事务加上 X 锁, 这时记录也是可以被读取的, 即读取的是快照数据.
在可重复读 (Repeatable Read) 下 MVCC 防止了部分幻读, 这里的"部分"是指在 一致性非锁定读 的情况下, 只能读取到第一次查询之前所插入的数据 (根据 Read View 判断数据可见性, Read View 在第一次查询时生成).
但是, 如果是 当前读, 每次读取的都是最新数据, 这时如果两次查询中间有其他事务插入数据, 就会产生幻读.
所以, InnoDB 在实现可重复读 (Repeatable Read) 时, 如果执行的是==当前读==, 则会对读取的记录使用 Next-key lock, 来防止其他事务在间隙间插入数据
# InnoDB 对 MVCC 的实现
MVCC 的实现依赖于 :
- 隐藏字段
Read Viewundo log
在内部实现中, InnoDB 通过数据行的 DB_TRX_ID 和 Read View 来判断数据的可见性.
如果数据不可见, 则通过数据行的 DB_ROLL_PTR 找到 undo log 中的历史版本. 每个事务读到的数据版本可能是不一样的, 在同一个事务中, 用户只能看到该事务创建 Read View 之前已经提交的修改和改事务本身做的修改
# 隐藏字段
在内部, InnoDB 存储引擎为每行数据添加了三个 隐藏字段 (opens new window) :
DB_TRX_ID(6 字节) : 表示最后一次插入或更新该行的事务 ID. 此外,delete操作在内部被视为更新, 只不过会在记录头Record header中的deleted_flag字段将其标记为已删除DB_ROLL_PTR(7 字节) : 回滚指针, 指向该行的undo log. 如果该行未被更新, 则为空DB_ROW_ID(6 字节) : 如果没有设置主键且该表没有唯一非空索引时,InnoDB会使用该 id 来生成聚集索引
# Read View
用途
Read View (opens new window) 主要是用来做 可见性判断, 里面保存了 "当前对本事务不可见的其他活跃事务"
字段
class ReadView {
/* ... */
private
trx_id_t m_low_limit_id; /* 大于等于这个 ID 的事务均不可见 */
trx_id_t m_up_limit_id; /* 小于这个 ID 的事务均可见 */
trx_id_t m_creator_trx_id; /* 创建该 Read View 的事务ID */
trx_id_t m_low_limit_no; /* 事务 Number, 小于该 Number 的 Undo Logs 均可以被 Purge */
ids_t m_ids; /* 创建 Read View 时的活跃事务列表 */
m_closed; /* 标记 Read View 是否 close */
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Read View 主要有以下字段 :
m_low_limit_id: 目前出现过的最大的事务 ID + 1, 即 下一个即将被分配的事务 ID, 大于等于这个 ID 的数据版本均不可见m_up_limit_id: 活跃事务列表m_ids中最小的事务 ID, 如果m_ids为空, 则m_up_limit_id为m_low_limit_id. 小于这个 ID 的事务版本均可见m_ids:Read View创建时其他未提交的活跃事务 ID 列表. 创建Read View时, 将当前未提交事务 ID 记录下来, 后续即使它们修改了记录行的值, 对于当前事务也是不可见的.m_ids不包括当前事务自己和已提交的事务 (正在内存中)m_creator_trx_id: 创建该Read View的事务 ID
事务可见性示意图

# undo log
作用
undo log 主要有两个作用 :
当事务回滚时用于将数据恢复到修改前的样子
同 隐藏字段,
Read View共同实现MVCC当读取记录时, 若该记录被其他事务占用或当前版本对该事务不可见, 则可以通过
undo log读取之前的版本数据, 以此实现非锁定读
类型
在 InnoDB 存储引擎中, undo log 分为两种 :
insert undo logupdate undo log
# insert undo log
insert undo log 指在 insert 操作中产生的 undo log
因为 insert 操作的记录只对事务本身可见, 对其他事务不可见, 故该 undo log 可以在事务提交后直接删除. 不需要进行 purge 操作
# 原理
insert时的数据初始状态
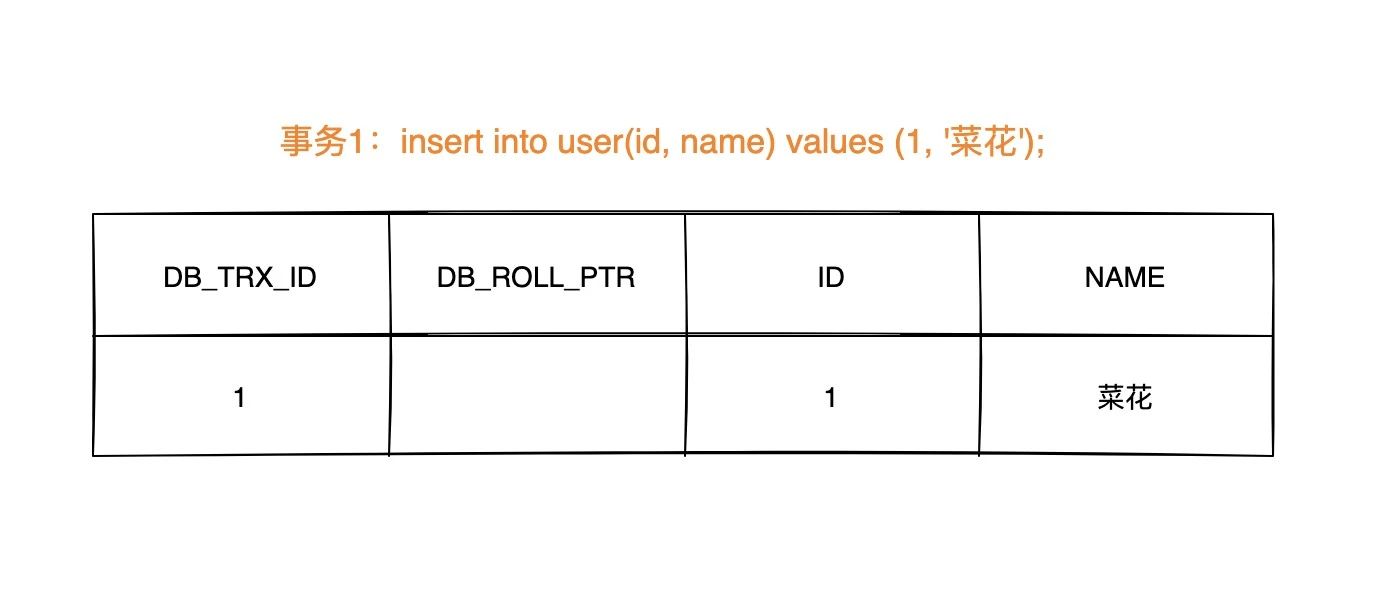
# update undo log
update undo log 是指在 update 或 delete 操作中产生的 undo log
该 undo log 可能需要提供 MVCC 机制, 因此不能在事务提交时就进行删除. 提交时放入 undo log 链表, 等待 purge 线程进行最后的删除
# 原理
数据第一次被修改时
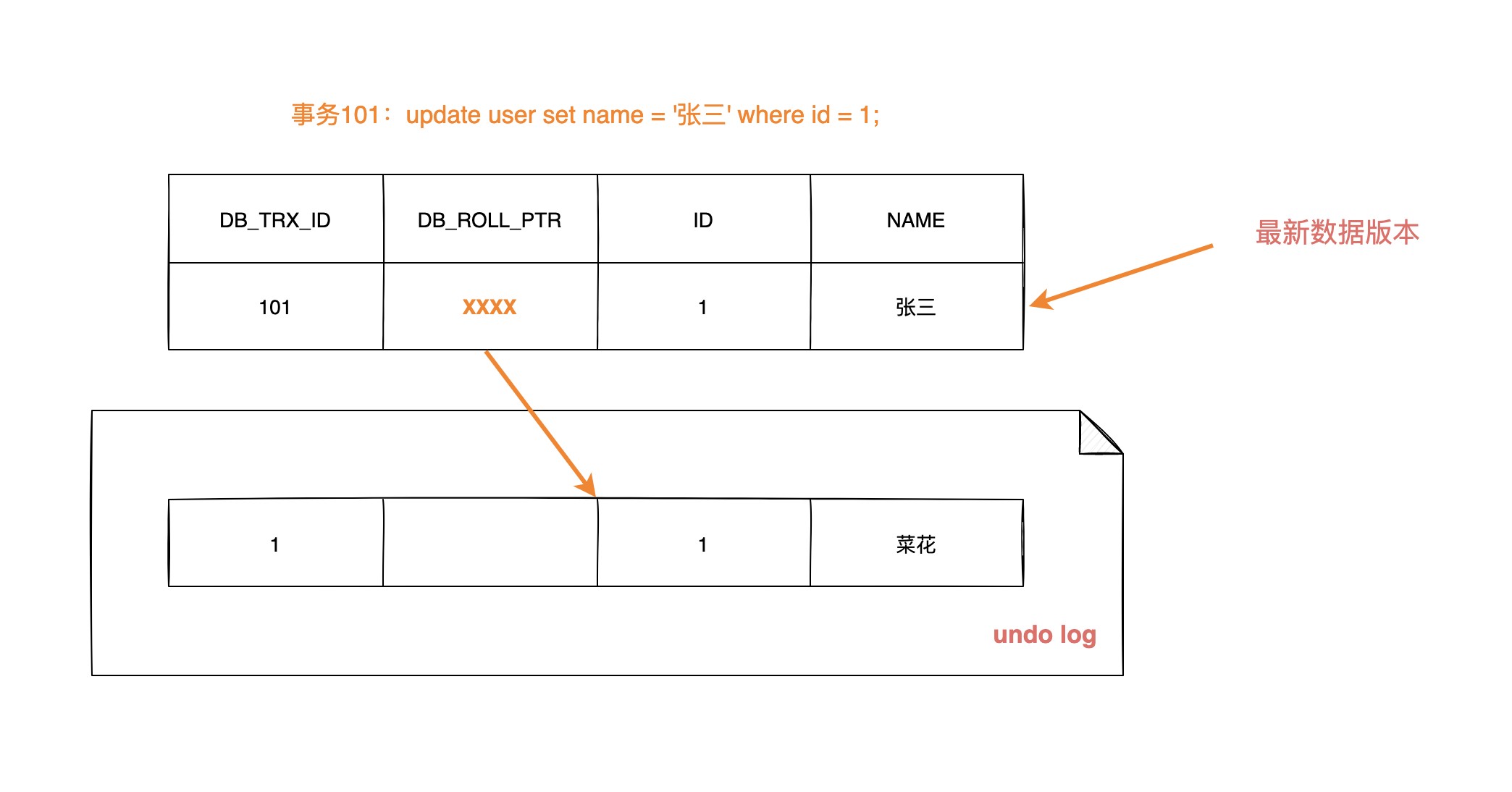
数据第二次被修改时
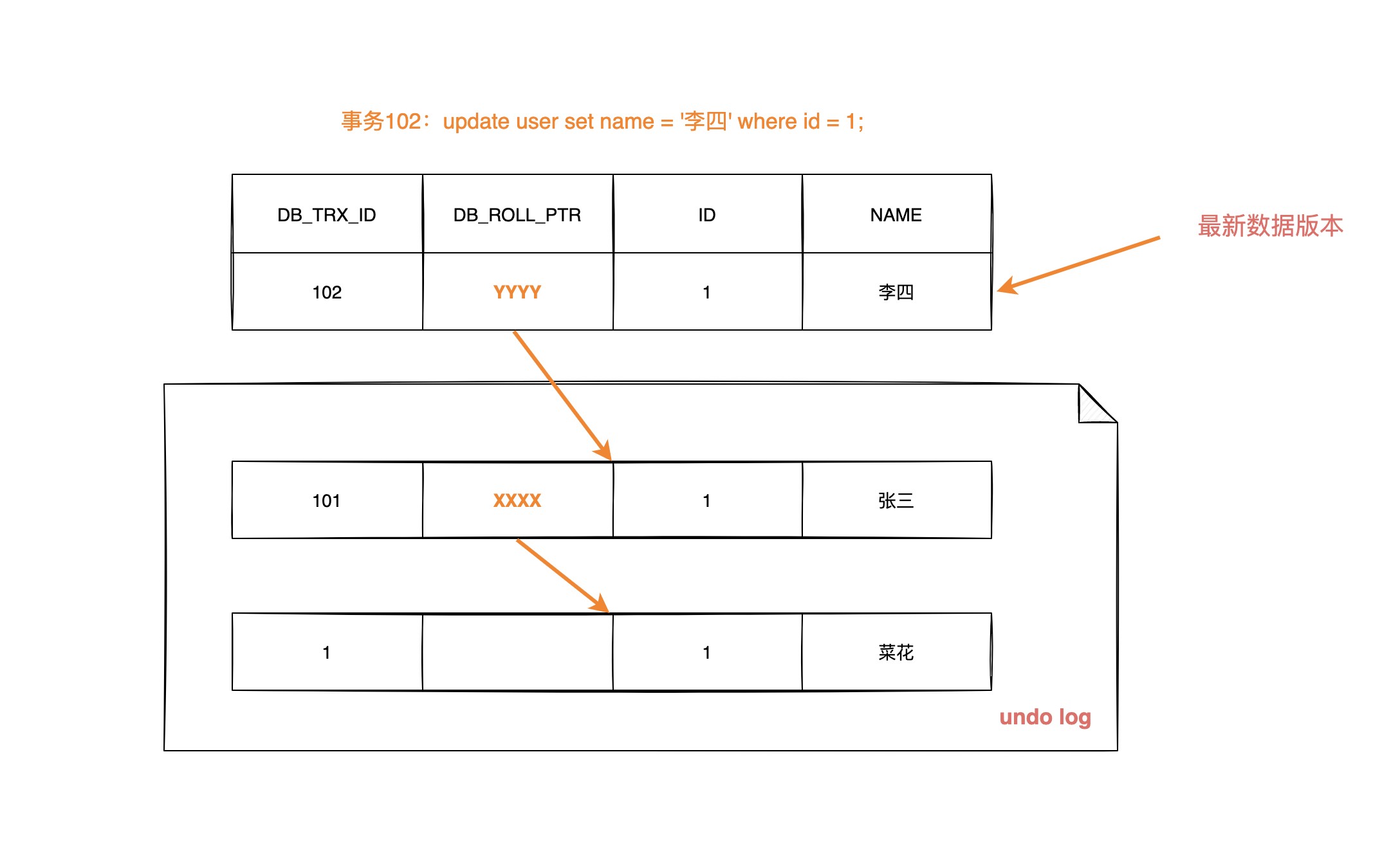
不同事务或者相同事务的对同一记录行的修改, 会使该记录行的 undo log 称为一条链表, 链首就是最新的记录, 链尾就是最早的旧记录
# 数据可见性算法
在 InnoDB 存储引擎中, 创建一个新事务后, 执行每个 select 语句前, 都会创建一个快照 (Read View), 快照中保存了当前数据库系统中正处于活跃 (没有 commit) 的事务的 ID 号. 其实简单的说保存的是系统中当前不应该被本事务看到的其他事务 ID 列表 (即 m_ids).
当用户在这个事务中尧都区某个记录行的时候, InnoDB 存储引擎会将该记录行的 DB_TRX_ID 与 Read View 中的一些变量及当前事务 ID 进行比较, 判断是否满足可见性条件
# 算法实现
算法原址 (github)
图示

# 算法原理
如果记录
DB_TRX_ID<m_up_limit_id, 那么表明最新修改该行的事务 (DB_TRX_ID) 在当前事务创建快照之前就提交了, 所以该记录行的值对当前事务是可见的如果
DB_TRX_ID>=m_low_limit_id, 那么表明最新修改该行的事务 (DB_TRX_ID) 在当前事务创建快照之后才进行修改, 所以该记录行的值对当前事务不可见. 跳到步骤 5m_ids为空, 则表明在当前事务创建快照之前, 修改该行的事务就已经提交了, 所以该记录行的值对当前事务是可见的如果
m_up_limit_id<=DB_TRX_ID<m_low_limit_id, 表明最新修改该行的事务 (DB_TRX_ID) 在当前事务创建快照的时候可能处于 "活动状态" 或者 "已提交状态". 所以就要对活跃事务列表m_ids进行查找 (因为事务 ID 是有序的, 所以使用二分查找)如果在活跃事务列表
m_ids中能找到DB_TRX_ID, 表名 :在当前事务创建快照前, 该记录行的值被事务 ID 为
DB_TRX_ID的事务修改了, 但没有提交在当前事务创建快照后, 该记录行的值被事务 ID 为
DB_TRX_ID的时候修改了这些情况下, 这个记录行的值对于当前事务都是不可见的. 跳到步骤 5
在活跃事务列表中找不到, 则表明 "ID 为
DB_TRX_ID的事务" 在修改 "该记录行的值" 后, 在 "当前事务" 创建快照之前就已经提交了, 所以记录行对当前事务可见
在改记录行的
DB_ROLL_PTR指针指向的undo log取出快照记录, 用快照记录的DB_TRX_ID跳到步骤 1 重新开始判断, 直到找到满足的快照版本或者返回空
# RC 和 RR 隔离级别下 MVCC 的差异
在事务隔离级别为 读已提交 (Read Commit) 和 可重复读 (Repeatable Read) 下, InnoDB 存储引擎使用 MVCC (非锁定一致性读), 但它们生成 Read View 的时机不同
- 在
RC隔离级别下, 每次select查询前都生成一个Read View(m_ids 列表) - 在
RR隔离级别下, 只有事务创建后, 第一次select数据前生成一个Read View(m_ids 列表)
# MVCC 解决不可重复读问题
虽然 RC 和 RR 都通过 MVCC 来读取快照数据, 但由于 生成 Read VIew 时机不同, 从而在 RR 级别下实现可重复读
例子

# 在 RC 下 Read View 生成情况
在读已提交级别下,事务在每次查询开始时都会生成并设置新的 Read View, (m_ids 列表)
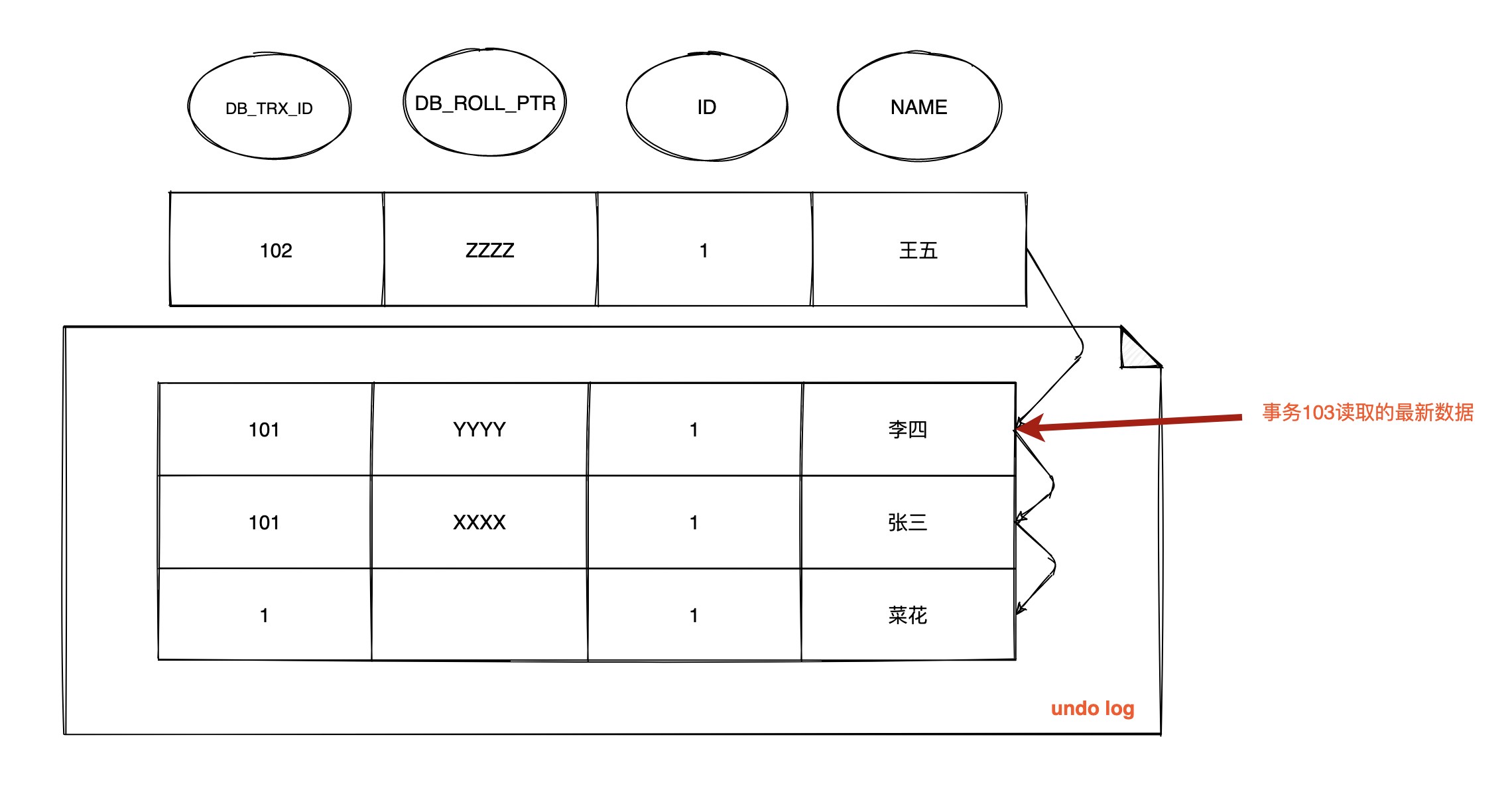
T4 时间点, 数据行 ID = 1 的版本链
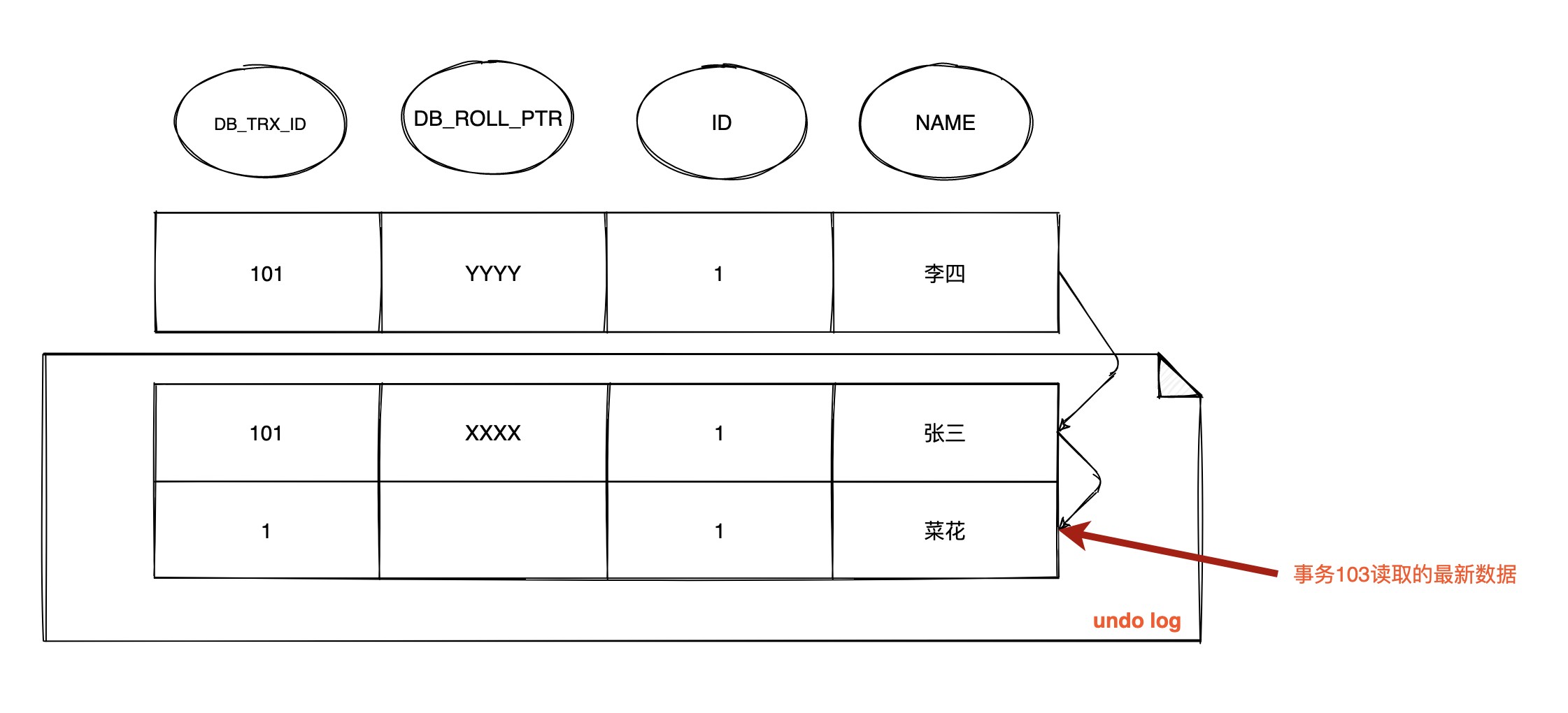
由于 RC 级别下每次查询都会生成 Read View, 这时事务 101, 102 并未提交
此时 **103 事务生成的 Read View 中活跃的事务 m_ids 为 [101, 102], m_up_limit_id 为 101, m_low_limit_id 为 104, m_creator_trx_id 为 103 **
- 此时最新记录的
DB_TRX_ID为 101,m_up_limit_id<= 101 <m_low_limit_id, 所以要在m_ids列表中查找, 发现DB_TRX_ID存在列表中, 那么这个记录不可见 - 根据
DB_ROLL_PTR找到undo log的上一版记录, 上一条记录的DB_TRX_ID还是 101, 不可见 - 继续找上一条
DB_TRX_ID为 1, 满足 1 <m_up_limit_id, 可见, 所以事务 103 在 T4 时间点查询到数据为name = 菜花
T6 时间点, 数据行 ID = 1 的版本链
由于 RC 级别下每次查询都会生成 Read View, 这时事务 101 已经提交, 事务 102 并未提交
此时 103 事务生成的 Read VIew 中活跃的事务 m_ids 为 [102], m_up_limit_id 为 102, m_low_limit_id 为 104, m_creator_rtx_id 为 103
- 此时最新记录中
DB_TRX_ID为 102,m_up_limit_id<= 102 <m_low_limit_id, 所以要在m_ids列表中查找, 发现DB_TRX_ID存在列表中, 那么这个记录不可见 - 根据
DB_ROLL_PTR找到undo log中的上一版本记录, 上一条记录的DB_TRX_ID为 101, 满足 101 <m_up_limit_id, 记录可见, 所以事务 103 在 T6 时间点查询到数据为name = 李四, 与 T4 事件单查询到的结果不一致, 不可重复读
T9 时间点, 数据行 ID = 1 的版本链
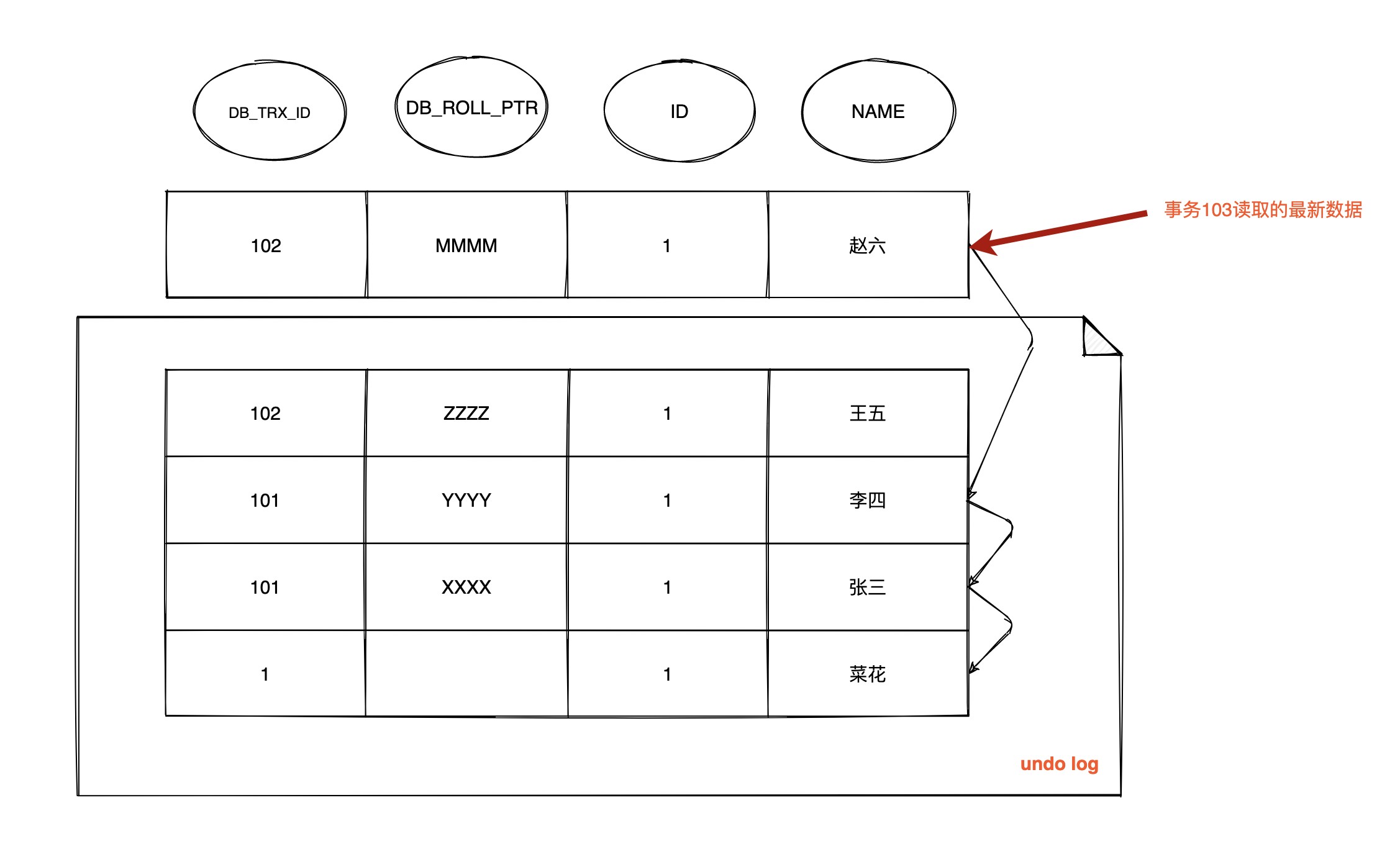
由于 RC 级别下每次查询都会生成 Read View, 这时事务 101, 102已经提交
此时 **103 事务生成的 Read View 中活跃的事务 m_ids 为 [], m_up_limit_id 为 104, m_low_limit_id 为 104, m_creator_trx_id 为 103, **
- 此时最新记录中
DB_TRX_ID为 102, 满足 102 <m_up_limit_id, 可见, 所以事务 103 在 T9 时间点查询到数据为name = 赵六, 与 T6 事件单查询到的结果不一致, 不可重复读
# 总结
在 RC 隔离级别下, 事务在每次查询开始时都会生成并设置新的 Read View, 所以导致不可重复读
# 在 RR 下 Read View 生成情况
在可重复读级别下, 只会在事务开始后第一次读取数据时生成一个 Read View (m_ids 列表)
T4 时间点, 数据行 ID = 1 的版本链
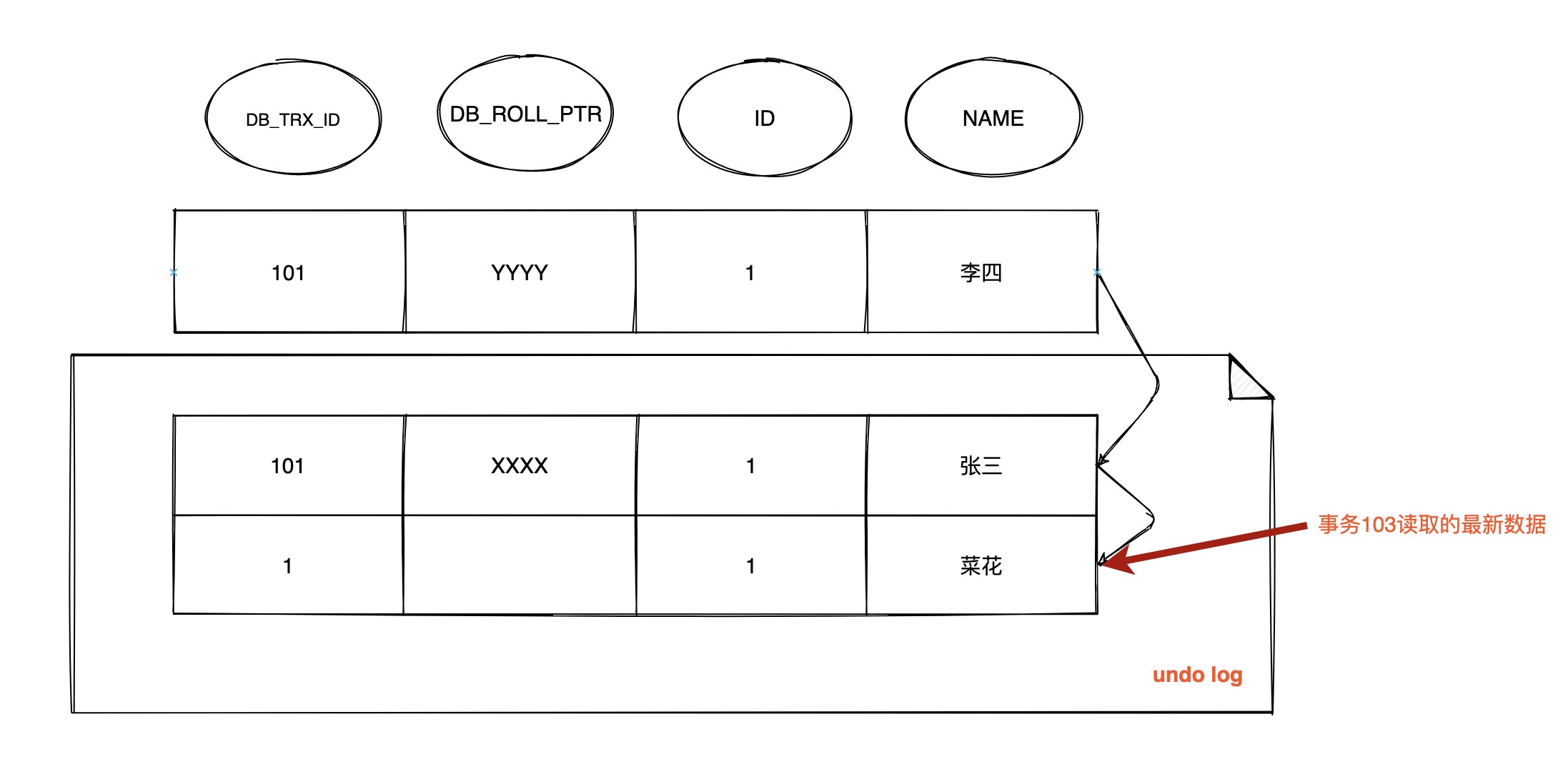
在当前执行 select 语句时生成一个 Read View
m_ids 为 [101, 102], m_up_limit_id 为 101, m_low_limit_id 为 104, m_creator_trx_id 为 103
此时和 RC 级别下一样 :
- 最新记录的
DB_TRX_ID为 101,m_up_limit_id<= 101 <m_low_limit_id, 所以要在m_ids列表中查找, 发现DB_TRX_ID存在列表中, 那么这个记录不可见 - 根据
DB_ROLL_PTR找到undo log的上一版记录, 上一条记录的DB_TRX_ID还是 101, 不可见 - 继续找上一条
DB_TRX_ID为 1, 满足 1 <m_up_limit_id, 可见, 所以事务 103 在 T4 时间点查询到数据为name = 菜花
T6 时间点, 数据行 ID = 1 的版本链
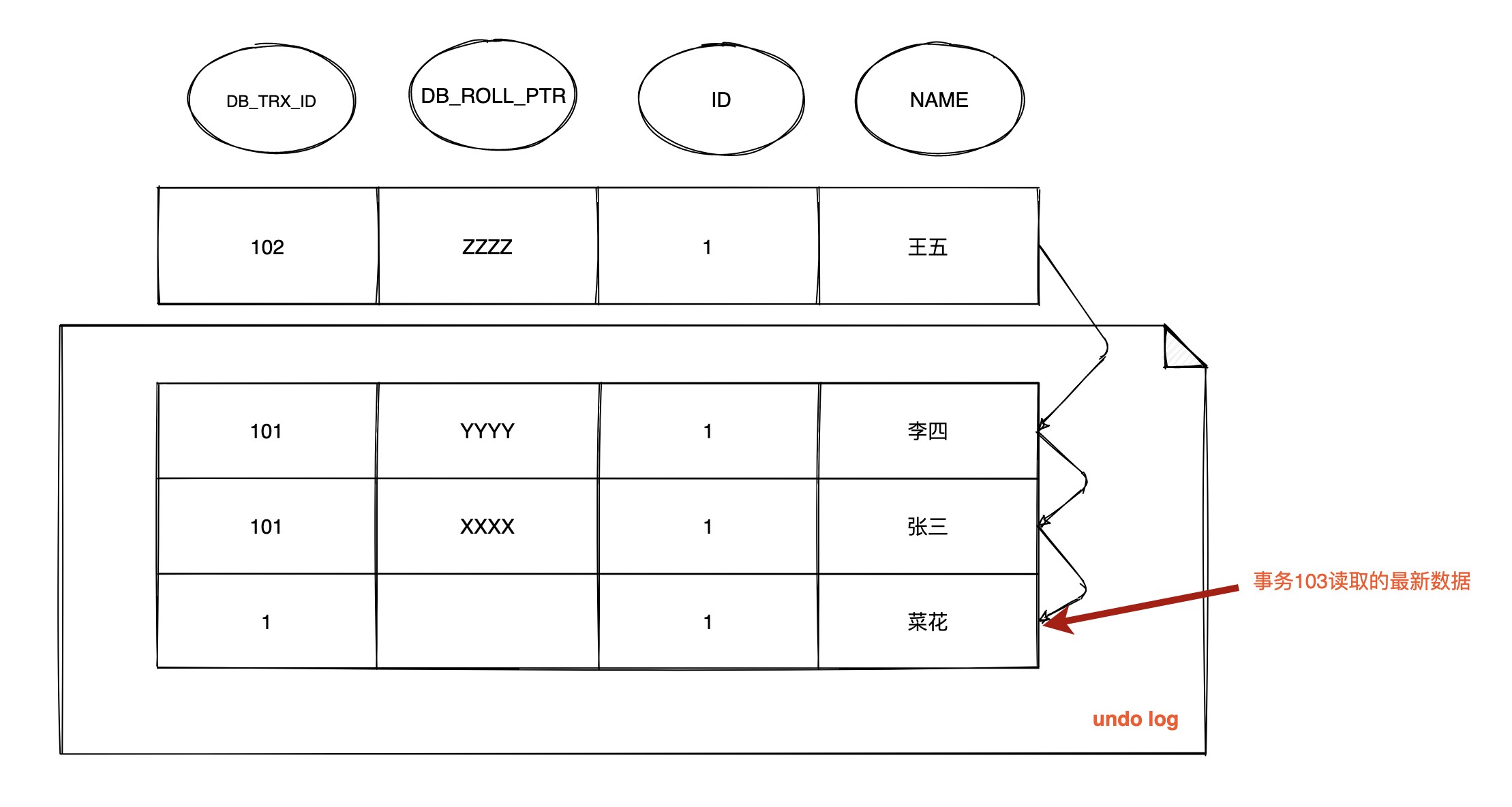
在 RR 级别下只会生成一次 Read View, 所以此时依然沿用 T4 时间点的 Read View
m_ids 为 [101, 102], m_up_limit_id 为 101, m_low_limit_id 为 104, m_creator_trx_id 为 103
- 最新记录的
DB_TRX_ID为 102,m_up_limit_id<= 102 <m_low_limit_id, 所以要在m_ids列表中查找, 发现DB_TRX_ID存在列表中, 那么这个记录不可见 - 根据
DB_ROLL_PTR找到undo log的上一版记录, 上一条记录的DB_TRX_ID是 101,m_up_limit_id<= 102 <m_low_limit_id, 所以要在m_ids列表中查找, 发现DB_TRX_ID存在列表中, 不可见 - 根据
DB_ROLL_PTR找到undo log的上一版记录, 上一条记录的DB_TRX_ID还是 101, 不可见 - 继续找上一条
DB_TRX_ID为 1, 满足 1 <m_up_limit_id, 可见, 所以事务 103 在 T4 时间点查询到数据为name = 菜花
T9 时间点, 数据行 ID = 1 的版本链
在 RR 级别下只会生成一次 Read View, 所以此时依然沿用 T4 时间点的 Read View
m_ids 为 [101, 102], m_up_limit_id 为 101, m_low_limit_id 为 104, m_creator_trx_id 为 103
此时情况和 T6 完全一样, 所以查询结果还是 name = 菜花
# 总结
在 RR 隔离级别下, 只会在事务开始后第一次读取数据时生成一个 Read View, 所以是可重复读的
# MVCC + Next-key-Lock 防止幻读
InnoDB 存储引擎在 RR 级别下通过 MVCC + Next-key-Lock 来解决幻读问题
解决方法主要分为两个方面 :
执行普通
select, 此时会以MVCC快照读的方式读取数据在快照读的情况下,
RR隔离级别只会在事务开启后的第一次查询生成Read View, 并使用至事务提交.所以在生成
Read View之后其他事务所做的更新, 插入记录版本对当前事务并不可见, 实现了可重复读和防止快照读下的 "幻读"执行
select ... for update / lock in share mode,insert,update,delete等当前读在当前读下, 读取的都是最新的数据, 如果其他事务有插入新的记录, 并且刚好在当前事务的查询范围内, 就会产生幻读.
InnoDB存储引擎使用 Next-key-Lock (opens new window) 来防止这种情况. 当执行当前读时, 会锁定读取到的记录的同时, 锁定它们的间隙, 防止其他事务在查询范围内插入数据. 只要我不让你插入, 就不会产生幻读